1.首先,运行Adobe Acrobat XI Pro软件,打开要提取文本的pdf文档,如下图所示:
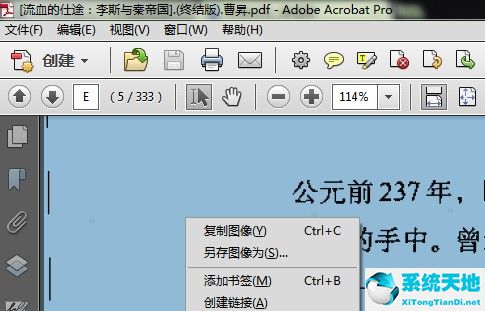
 2,定位到要提取文字的页面,选中,右键看到当前页面是图片,如下图所示:
2,定位到要提取文字的页面,选中,右键看到当前页面是图片,如下图所示:
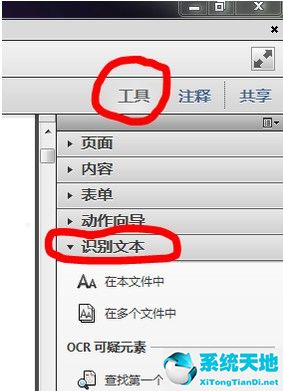
:  3.在Adobe Acrobat XI Pro软件工具栏的右侧,依次找到工具——识别文本,如下图所示:
3.在Adobe Acrobat XI Pro软件工具栏的右侧,依次找到工具——识别文本,如下图所示:
:  4.单击“在此文件中”打开识别文本的窗口。为了方便,我选择了当前页面,设置中的内容一般不设置。如有必要,可以点击【编辑】按钮修改设置项目,如下图所示:
4.单击“在此文件中”打开识别文本的窗口。为了方便,我选择了当前页面,设置中的内容一般不设置。如有必要,可以点击【编辑】按钮修改设置项目,如下图所示:
:  5.点击确定后,软件会自动分析当前页面,然后自动识别其中的文本,如下图所示:
5.点击确定后,软件会自动分析当前页面,然后自动识别其中的文本,如下图所示:
:  6.识别后仍停留在当前页面。不同的是,当你再次右击文本时,可以看到熟悉的副本,也可以选择“将所选项目导出为……”,如下图所示:
6.识别后仍停留在当前页面。不同的是,当你再次右击文本时,可以看到熟悉的副本,也可以选择“将所选项目导出为……”,如下图所示:
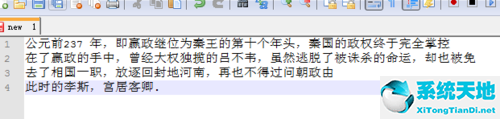
:  7.复制后,粘贴到文本文档或需要的地方即可。如下图所示,pdf中的文本被提取出来。
7.复制后,粘贴到文本文档或需要的地方即可。如下图所示,pdf中的文本被提取出来。
未经允许不得转载:探秘猎奇网 » adobepdf提取页面(adobe怎么提取pdf)
 Word怎样批量替换相同文字(word里怎么批量替换文字)
Word怎样批量替换相同文字(word里怎么批量替换文字) 360随身wifi怎么自动开启(360随身wifi关闭了自启还是开机自启)
360随身wifi怎么自动开启(360随身wifi关闭了自启还是开机自启) 一斤小龙虾大概有多少只?龙虾几月份比较好吃呢
一斤小龙虾大概有多少只?龙虾几月份比较好吃呢 EMO是什么意思网络用语,EMO作为一种红极一时的艺术形式
EMO是什么意思网络用语,EMO作为一种红极一时的艺术形式 windows无法清除dns缓存(无法完成清除dns缓存)
windows无法清除dns缓存(无法完成清除dns缓存) wsappx占用大量cpuwin10(win11占用运行内存)
wsappx占用大量cpuwin10(win11占用运行内存) excel2013表格一动就未响应(excel表格一动就未响应怎么办)
excel2013表格一动就未响应(excel表格一动就未响应怎么办) 几何画板三棱锥展开图(几何画板画棱锥)
几何画板三棱锥展开图(几何画板画棱锥)



























